Arkusze Google Sheets dla SEO i PPC

Arkusze Google to przydatne potężne narzędzie jeżeli chodzi o codzienną pracę specjalisty SEO albo specjalisty Google Ads. Zebrałem najczęściej wykorzystywane przeze mnie funkcje możliwości arkuszy Google. Mam nadzieję, że Tobie też pomogą. Wpis jest na bieżąco aktualizowany!
Na tej stronie:
pokaż
Zanim skopiujesz
Przed skorzystaniem upewnij się, że korzystasz ze średnika jako elementu rozdzielającego argumenty w formułach!
Opis wykorzystywanych funkcji Google Sheets
IMPORTXML
Jedna z moich ulubionych funkcji Google Sheets! Funkcja importuje dane z różnych typów danych strukturalnych, w tym XML, HTML, CSV, TSV oraz kanałów informacyjnych RSS i ATOM XML. W swojej składni wykorzystuje adres URL oraz zapytanie XPath.
XPath wykorzystuje się do nawigacji po elementach strony na podstawie ich atrybutów. Te same ścieżki elementów można z powodzeniem wykorzystywać w crawlerach takich jak Screaming Frog. Więcej na temat XPath możesz przeczytać tutaj:
- https://www.w3schools.com/xml/xpath_intro.asp
- https://developer.mozilla.org/pl/docs/Web/XPath
Importowanie adresów URL z mapy witryny
Jeżeli masz mapę witryny i chciałbyś pobrać z niej wszystkie adresy URL, to możesz się męczyć ręcznie i kombinować z kopiowaniem i wklejaniem albo skorzystać z formuły IMPORTXML.
IMPORTXML("https://AdresURL/MapyWitryny.xml"; "//*[local-name() ='url']/*[local-name() ='loc']")Code language: JavaScript (javascript)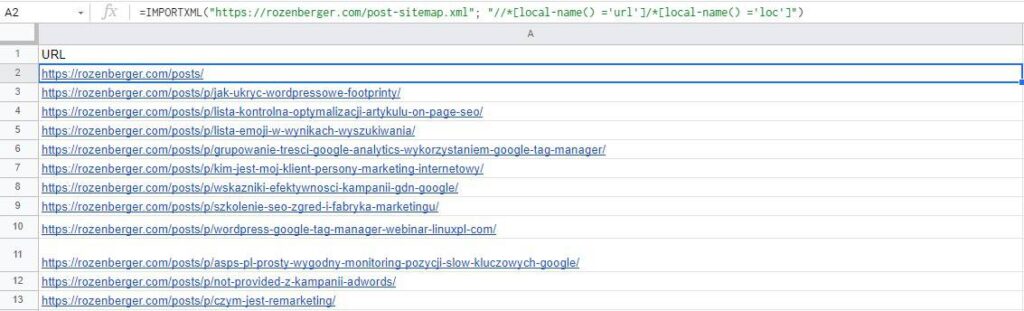
Importowanie różnych elementów strony do Google Sheets
W formule Import XML możemy podać ścieżkę XPath, z której arkusz ma pobrać dane. Możemy w ten sposób pobrać autora tekstu, datę, liczbę komentarzy, kategorie, tagi.
Co więcej w ten sposób możesz pobierać np. ceny produktów u konkurencji lub nazwę stosowaną przez konkurencję.
Ekstrakcję możemy wykonać dla dowolnego elementu ze strony. Aby pobrać ścieżkę elementu należy w konsoli dla programistów kliknąć prawy przycisk na interesującym nas elemencie i pobrać ścieżkę XPath lub pełną ścieżkę XPath.
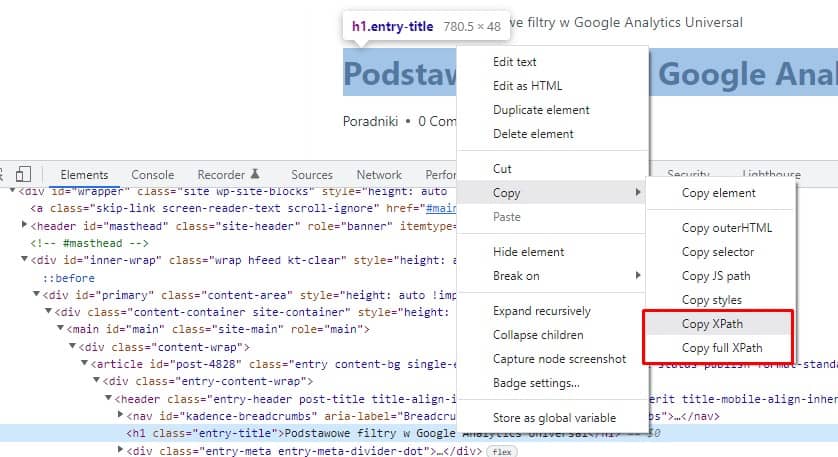
Import meta tytułu
=IMPORTXML(A2;"//title")Code language: JavaScript (javascript)Import H1
=IMPORTXML(A2;"//h1")Code language: JavaScript (javascript)Pobranie tylko pierwszego znalezionego elementu
=IMPORTXML(A2;"//h1[1]")Code language: JavaScript (javascript)Import H2
Pobranie wszystkich elementów H2
| =IMPORTXML($A2;”//*/h2 |
Pobranie tylko pierwszego znalezionego elementu
| =IMPORTXML(A2;”//*/h2[1]”) |
Pobranie wszystkich elementów i umieszczenie ich w jednej komórce, rozdzielone przecinkiem i spacją
| =TEXTJOIN(„, „;TRUE;IMPORTXML($A2;”//*/h2”)) |
Policzenie liczby występujących H2
| =COUNTA(SPLIT(E2;”,%20″;TRUE;TRUE)) |
Import Canonical
| =IMPORTXML(A2;”//link[@rel=’canonical’]/@href”) |
Sprawdzenie czy Canonical wskazuje sam na siebie. Przyjmuje wartość TRUE jeżeli są takie same.
| =($A2=$J2) |
Import Meta Robots
| =IMPORTXML($A2;”//meta[@name=’robots’]/@content”) |
Sprawdzenie czy Meta Robots jest index
| =IF(REGEXMATCH($H2; „noindex”); „noindex”; „index”) |
Sprawdzenie czy Meta Robots jest index
| =IF(REGEXMATCH($H2; „nofollow”); „nofollow”; „follow”) |
Obliczanie różnicy dat
Za pomocą Google Sheets możesz sprawdzić daty publikacji i obliczyć kiedy jak dawno zostało coś ostatnio opublikowane. Możesz też wykorzystać daty planowych publikacji w content planie.
Wykorzystuje się do tego obliczenia arytmetyczne i funkcję TODAY() lub w polskim interfejsie DZIŚ().
Jak dawno był wpis
| =TODAY()-A2 |
Ile zostało dni pozostało
| =B3-TODAY() |
Obróbka adresów URL
Wyciąganie ścieżki z adresu URL
| =RIGHT(A2;LEN(A2)-FIND(„/”;A2;FIND(„/”;A2)+2)+1) |
Usunięcie parametrów z adresu URL
| =IFERROR(LEFT(A2;FIND(„?”;A2)-1);”No parameter in URL”) |
Sprawdzenie parametrów z adresu URL
| =IFERROR(RIGHT(A2;LEN(A2)-FIND(„?”;A2));”No parameter in URL”) |
Wyciąganie subdomeny z adresu URL
| =REGEXREPLACE(A2;”http\:\/\/|https\:\/\/|\/.*|\?.*|\#.*”;””) |
Wyciąganie domeny z adresu URL (root)
Zwróć uwagę na to, że w formule jest wpisane www i blog, więc jeśli chcesz pozbyć się innej subdomeny, to musisz zmienić to w formule. Głównie chodzi nam tutaj o pozbycie się www.
| =REGEXREPLACE(A2;”http\:\/\/|https\:\/\/|www\.|blog\.|\/.*|\?.*|\#.*”;””) |
Wyciąganie TLD z adresu URL
| =REGEXREPLACE(A2;”.*\.|\/.*”;””) |
Sprawdzenie trailing slash dla adresu
| =IF(RIGHT(A2;1)=”/”;”Ends with a trailing slash”;”Does not end with a trailing slash”) |
Sprawdzenie protokołu
| =LEFT(A2;(FIND(„:”;A2)-1)) |